消费者
消息中间件有2种投递模式:
-
点对点(P2P)
基于队列,消息生产者发送消息到消息队列,消费者从队列中获取消息
当Kafka消费组只有一个,则消息只会被投递到该消费组中的消费者,相当于点对点 -
发布订阅(Pub/Sub)
基于主题,生产者将消息发布到某个主题,消费者从主题中订阅消息,生产和消费者二者保持独立
当Kafka消费组有多个时,每个消息都会被多个消费组处理,相当于发布/订阅
消费者和消费组
消费者
负责订阅topic的主题,从订阅的主题中拉取poll消息
消费组
每个消费者都只有一个消费组对应,一个消费组的消费者实例可以在不同机器上。
当消息主题被订阅后,只会被投递给订阅的消费组中的一个消费者
3者联系
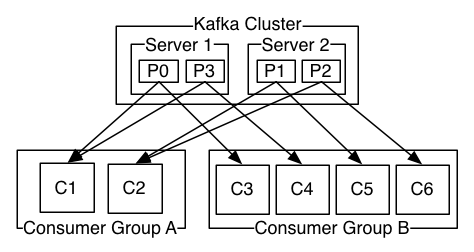
- 上图一个kafka集群有2个broker server1和server2
- 每个broker的同一个topic分配2个分区partition
- 2个consumer消费组,其中A有2个消费者 B有4个消费者,都订阅了相同的topic
- 默认A中的每个消费者分配到2个分区,B每个只分配到1个,如果再多出一个consumer则会有空闲
结论
- 同一个topic下,每个分区partition只会被投递给订阅的消费组中的一个消费者
- 当消费者多于分区时,会得不到分配分区
- 可以扩充分区和消费组中的消费者数量来进行横向弹性伸缩
客户端开发
- 消费者逻辑
1.配置消费者客户端参数创建消费者实例
2.订阅主题
3.拉取消息并消费
4.提交消费位移
5.关闭消费者实例
public class KafkaConsumerAnalysis {
private static final String brokerList = "";
private static final String topic = "topic-demo";
private static final String groupId = "group.demo";
private static final AtomicBoolean isRunningg = new AtomicBoolean(true);
public static Properties initConfig() {
Properties props = new Properties();
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
props.put("bootstrap.servers", brokerList);
props.put("group.id", groupId);
props.put("client.id", "consumer.client.id.demo");
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
/**
* 订阅主题
* 1。如果以集合形式订阅则每次调用会覆盖以前订阅的集合
*/
consumer.subscribe(Collections.singleton(topic));
/**
* 2。如果以正则表达式订阅,则后续上线的新的主题也会被订阅,使用较多
*/
// consumer.subscribe(compile("topic-.*"));
/**
* 订阅分区,不允许增量,会覆盖以前的
*/
// consumer.assign(Collections.singletonList(new TopicPartition("topic-demo", 0)));
//查询指定主题的元数据信息
List<PartitionInfo> partitionInfos = consumer.partitionsFor(topic);
ArrayList<TopicPartition> topicPartitions = new ArrayList<>();
//只获取指定分区集的消费信息
partitionInfos.forEach(v -> topicPartitions.add(new TopicPartition(v.topic(), v.partition())));
// consumer.assign(topicPartitions);
/**
* 取消订阅,可以订阅后取消后再订阅
* 1。调用unsubscribe方法
* 2。subscribe一个空的集合string
* 3。assign一个空的集合TopicPartition
*/
// consumer.unsubscribe();
try {
while (isRunningg.get()) {
/**
* 设置拉取超时时间,如果为0则会立即返回,不管是否拉取到消息。
* 如果是单独开的线程,则可以将其设置为超长时间最大值
*
* poll涉及消费位移、消费者协调器、组协调器、消费者选举、分区分配的分发、再均衡、心跳
*
*/
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
records.forEach(v -> {
System.out.println("topic = " + v.topic() + ", partition = " + v.partition() + ", offset= " + v.offset());
System.out.println("key = " + v.key() + ", value = " + v.value());
log.info("headers:{}",v.headers());
//如果序列化之后的值大小为为空则返回-1,否则返回序列化的大小
log.info("serializedKeySize:{}",v.serializedKeySize());
log.info("serializedValueSize:{}",v.serializedValueSize());
log.info("timestamp:{}",v.timestamp());
log.info("timestampType:{}",v.timestampType());
//TODO 处理消息
});
/**
* 按照分区纬度来处理消息
* 1.获取返回记录包含的分区set集合,如果未返回数据,则可能为空
* 2。获取指定分区的消息
*/
records.partitions().forEach(v->{
records.records(v).forEach(v1->{
//TODO 每个不同的分区处理
});
});
/**
* 按主题纬度来进行消费
* 根据订阅时的列表来处理
*
*/
ArrayList<String> topics = new ArrayList<>();
partitionInfos.forEach(v->topics.add(v.topic()));
topics.forEach(v->{
records.records(v).forEach(v1->{
//TODO 每个不同的主题topic处理
});
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}