客户端
Redis服务单和客户端的通信协议,主流编程语言的Redis客户端使用方法,客户端管理的相应API及相关问题
客户端通信协议
几乎所有的主流编程语言都有Redis的客户端
https://redis.io/clients

- 技术角度通信原因:
1.客户端与服务端通信协议在TCP基础上构建的
2.Redis制定了RESP(REdis Serialization Protocol,Redis序列化协议),该协议简单高效,既能够被机器解析,又容易被人类识别
发送命令格式
RESP的规定一条命令的格式如下,CRLF代表"\r\n"
*<参数数量> CRLF
$<参数1的字节数量> CRLF
<参数1> CRLF
...
$<参数N的字节数量> CRLF
<参数N> CRLF
以 set hello world 为例
*3
$3
SET
$5
hello
$5
world
返回结果格式
Redis的返回结果类型分为以下五种
- 状态回复:在RESP中第一个字节为"+"
- 错误回复:在RESP中第一个字节为"-"
- 整数回复:在RESP中第一个字节为":"
- 字符串回复:在RESP中第一个字节为"$"
- 多条字符串回复:在RESP中第一个字节为"*"
Java客户端Jedis
除Jedis客户端外还有其他很多客户端spring-data-redis等

获取Jedis
- 1.直接下载目标版本的Jedis-$.jar包加入到项目中
- 2.使用继承构建工具maven、gradle等


对于第三方开发包,版本的选择也是至关重要的,Redis的更新速度比较快,如果客户端跟不上服务端的速度,有些特性和bug不能及时更新,不利于日常开发
- 选择比较稳定的版本
- 选择更新活跃的第三方开发包,使得客户端可以支持新特性
Jedis的基本使用方法

public class Example {
public static void main(String[] args) {
//获取Redis实例
Jedis jedis = new Jedis("127.0.0.1", 6379);
//操作Redis
jedis.set("hello","world");
String hello = jedis.get("hello");
//输出获得的值
System.out.println(hello);
}
}
初始化Jedis需要2个参数:Redis实例的IP和端口,还有其他常用的构造函数

其构造函数很多,常用的参数有
public Jedis(final String host, final int port, final int connectionTimeout, final int soTimeout) {
super(host, port, connectionTimeout, soTimeout);
}
-
参数说明:
host:Redis实例的所在机器的IP
Redis实例的端口
connectionTimeout:客户端连接超时
soTimeout:客户端读写超时 -
及时关闭Jedis连接资源比较重要
@Slf4j
public class Example {
public static void main(String[] args) {
Jedis jedis = null;
try {
jedis = new Jedis("localhost", 6379);
String hello = jedis.get("hello");
System.out.println(hello);
} catch (Exception e) {
log.error(e.getMessage(), e);
} finally {
if (jedis != null) {
jedis.close();
}
}
}
}

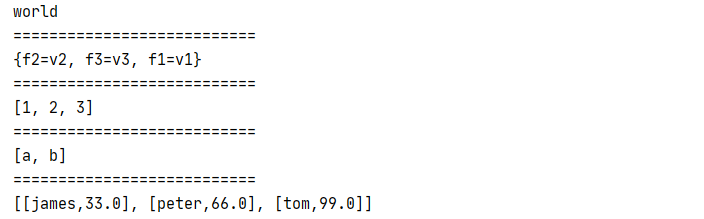
Jedis对于Redis五种数据结构的操作
@Slf4j
public class Example {
public static void main(String[] args) {
Jedis jedis = null;
try {
jedis = new Jedis("127.0.0.1", 6379);
//string
jedis.set("hello", "world");
String hello = jedis.get("hello");
System.out.println(hello);
System.out.println("===========================");
//hash
jedis.hset("myhash", "f1", "v1");
jedis.hset("myhash", "f2", "v2");
jedis.hset("myhash", "f3", "v3");
Map<String, String> map = jedis.hgetAll("myhash");
System.out.println(map);
System.out.println("===========================");
//list
jedis.rpush("mylist", "1");
jedis.rpush("mylist", "2");
jedis.rpush("mylist", "3");
List<String> mylist = jedis.lrange("mylist", 0, -1);
System.out.println(mylist);
System.out.println("===========================");
//set
jedis.sadd("myset", "a");
jedis.sadd("myset", "b");
jedis.sadd("myset", "a");
Set<String> myset = jedis.smembers("myset");
System.out.println(myset);
System.out.println("===========================");
//zset
jedis.zadd("myzset", 99, "tom");
jedis.zadd("myzset", 66, "peter");
jedis.zadd("myzset", 33, "james");
Set<Tuple> myzest = jedis.zrangeByScoreWithScores("myzest", 0, 100);
System.out.println(myzest);
System.out.println("===========================");
} catch (Exception e) {
log.error(e.getMessage(), e);
} finally {
if (jedis != null) {
jedis.close();
}
}
}
}
上面的Tuple数据结构如下

zrangeByScoreWithScores方法如下

执行结果如下
Jedis连接池的使用方法
类似Druid和C3P0等连接池一样,每次创建新的对象并不是高效的方式,使用连接池进行管理
Jedis的JedisPool类作为连接池

/**
* @Author jtao
* @Date 2021/1/10 20:59
* @Description
*/
@Slf4j
public class Example {
public static void main(String[] args) {
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
JedisPool jedisPool = new JedisPool(poolConfig, "127.0.0.1", 6379);
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
jedis.flushAll();
jedis.set("hello", "world");
System.out.println(jedis.get("hello"));
} catch (Exception e) {
log.error(e.getMessage(),e);
}
finally {
if(jedis!=null)
{
jedis.close();
}
}
}
}
该处的jedis.clos并非断开连接,源码如下:
@Override
public void close() {
if (dataSource != null) {
JedisPoolAbstract pool = this.dataSource;
this.dataSource = null;
if (client.isBroken()) {
pool.returnBrokenResource(this);
} else {
pool.returnResource(this);
}
} else {
super.close();
}
}
其判断是否使用连接池,如果使用,则归还连接给连接池,如果未使用则段开连接
Redis中Pipeline的使用方法
该Pipeline批量操作虽然不是原生具有原子性,但在绝大数场景下可以使用
/**
* @Author jtao
* @Date 2021/1/10 21:09
* @Description
*/
@Slf4j
public class Example {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost", 6379);
Pipeline pipeline = jedis.pipelined();
Map stringHashMap = new HashMap<String, String>();
jedis.flushAll();
jedis.mset("a","1","b","2","c","3");
System.out.println(jedis.keys("*"));
ArrayList<String> strings = new ArrayList<>();
strings.add("a");
strings.add("b");
strings.add("c");
String string=null;
strings.stream().forEach(vo-> {
pipeline.del(vo);
});
pipeline.sync();
Set<String> keys = jedis.keys("*");
System.out.println(keys);
}
}
结果如下图

在执行Pipeline之前无法使用Jedis,"Cannot use Jedis when in Pipeline. Please use Pipeline or reset jedis state ."报错如下:

Jedis的Lua脚本
Python 客户端redis-py
客户端管理
介绍各个API的使用以及在开发运维中可能遇到的问题
客户端API
client list:列出与Redis服务端相连的所有客户端连接信息

- 标识:id、addr、fd、name
id:客户端连接的唯一标识,随着Redis的连接自增,重启Redis后重置为0
addr:客户端IP地址和端口
fd:socket的文件描述
name:客户端的名字 - 输入缓冲区:qbuf、qbuf-free
qbuf:缓冲区总容量
qbuf-free:缓冲区剩余容量
一旦某个客户端的输入缓冲区超过1G,客户端将会被关闭
输入缓冲区不受maxmemory控制,超过maxmemory限制,可能会产生数据丢失、键值淘汰、OOM等情况
造成缓冲区过大的原因:
1.Redis处理苏跟不上缓冲区的输入速度,且每次进入输入缓冲区的命令包含了大量bigkey
2.Redis发生了阻塞,短期内不能处理命令,造成命令积压在缓冲区
发现于监控:
1.定期执行client list命令,收集qbuf和qubf-free找到异常的连接记录和客户端
2.通过info client找到最大的输入缓冲区,设置超过多大内存进行报警
- 输出缓冲区:obl、oll、omem
Redis为每个客户端分配了输出缓冲区,作用为保存命令执行的结果返回给客户端,为Redis和客户端交互返回结果提供缓冲,可以通过client-output-buffer-limit来进行设置
obl:固定缓冲区的长度
oll:动态缓冲区列表的长度
omem:使用的字节数 - 客户端的存活状态:age、idle
age:当前客户端已经连接时间
idle:最近一次的空闲时间
客户端的限制:maxclients和timeout
-
参数
maxclients:限制最大客户端连接数,超过则连接会被拒绝
time:限制连接最大空闲时间,一旦超过了timeout则连接会被关闭 -
info client获取Redis连接数

-
config get maxclients|timeout
config get maxclients:设置最大链接数,默认为10000
config get timeout:设置超时时间,默认为0,则不限制

-
config set maxclients number|timeout time

总结:默认的Redis的配置timeout=0,这种情况下客户端基本不会出现异常,这是基于对于客户端开发的一种保护。但是如果Redis的客户端使用不当或者客户端本身的一些问题,造成没有及时释放客户端连接,可能会造成大量的idle连接占据着很多连接资源,一旦超过maxclients则后果很严重。所以实际开发运维中,需要将timeout设置成大于0,例如可设置为300秒,同时在客户端使用上添加空闲检测和验证等等机制
客户端类型:flags
flags=S为slave客户端,flags=N为普通客户端,flags=O客户端增在执行monitor命令
client setName/getName:设置当前客户端名字,获取当前客户端名字
在Redis只有一个应用方使用的情况下,IP和端口作为标识会更加清晰。当多个应用方共同使用一个Redis,那么此时clien setName可以作为标识客户端的一个依据
client kill ip:port :杀掉指定IP地址和端口的客户端
client pause timeout(毫秒):设置阻塞客户端timeout毫秒数,在此期间客户端连接将被阻塞
monitor:监控Redis正在执行的命令

如上图启动2个client端,一个执行monitor监控,一个操作
可以鉴定Redis正在执行的命令,但每个客户端都有自己的输出缓冲区,一旦Redis的并发量过大,monitor可以监听到所有命令,则monitor客户端的输出缓冲区可能会爆涨,瞬间会占用大量内存
客户端相关配置
- tcp-keepalive:检测TCP连接活性的周期,默认值为0,即不进行检测,可以设置为60(Redis每隔60秒对它创建的TCP连接进行呵呵活性检测,防止大量死链接占用系统资源)
- tcp-backlog:TCP三次握手后,会将接收的链接放入队列中,top-backlog就是队列的大小,它在Redis中的默认值是511
客户端统计片段:info clients|stats
info-clients

- 参数如下:
connected_clients:当前Redis节点的客户端连接数
client_recent_max_input_buffer:当前所有输入缓冲区占用的最大容量
client_recent_max_output_buffer:当前所有输出缓冲区中队列对象个数的最大值
blocked_clients:正在执行阻塞命令(blpop、brpop、brpoplpush等)的客户端个数
info stats
- 主要参数:
total_connections_received:Redis启动以来处理的客户端连接数总数
rejected_connections:Redis启动以来拒接的的客户端连接数,需重点监控
客户端常见异常:Jdis客户端
无法从连接池获取到链接
- 高并发下连接池设置过小,出现供不应求
- 没有正确使用连接池,例如没有释放连接
- 存在满查询操作,持有的Jedis对象归还速度比较慢
- Redis服务端某些原因造成Redis客户端命令执行过程阻塞
客户端读写超时
- 读写超时设置过短
- 命令本身比较慢
- 客户端于服务端网络不正常
- Redis自身发生阻塞
客户端连接超时
- 连接超时设置过短
- Redis发生阻塞,造成tcp-backlog已满,造成新的连接失败
- 客户端于服务端网络不正常
客户端缓冲区异常
- 缓冲区满
- 长时间连接闲置被服务端主动断开
- 不正常并发读写:Jedis对象同时被多个线程并发操作
Lua脚本正在执行
Redis正在加载持久化文件
Redis使用的内存超过maxmemory配置
客户端连接数过大
该问题比较棘手,因为此时无法执行Redis命令进行问题修复
- 客户端:如果maxclients参数不是很小的话,通常是由于应用方对于Redis客户端使用不当造成的
- 服务端:如果此时客户端无法处理,而当前Redis为高可用模式(Redis Sentinel、Redis Cluster),可以考虑将当前Redis做故障转移