第十八章 并行(Parallel)Stream
使用并行 Streams,包括reduction、decomposition、merging、pipelines和performance。
什么是并行Parallel Stream
- 顺序流
其中每个元素都是一个接一个地处理的 - 并行流
将流分成多个部分。每个部分由不同的线程同时(并行)处理
使用 Fork/Join 并发框架。默认情况下,可用于处理并行流的线程数等于机器处理器的可用内核数
创建并行Stream
BaseStream接口方法

通过BaseStream接口的方法创建并行流
Stream<String> parallelStream =
Stream.of("a","b","c").parallel();

如果为并行Stream,设置管道的并行属性为true
Collection接口方法
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
parallelStream ()方法从 Collection 创建并行流
List<String> list = Arrays.asList("a","b","c");
Stream<String> parStream = list.parallelStream();
并行Parallel Streams适合无状态操作
Stream.of("a","b","c","d","e")
.parallel()
.forEach(System.out::print);
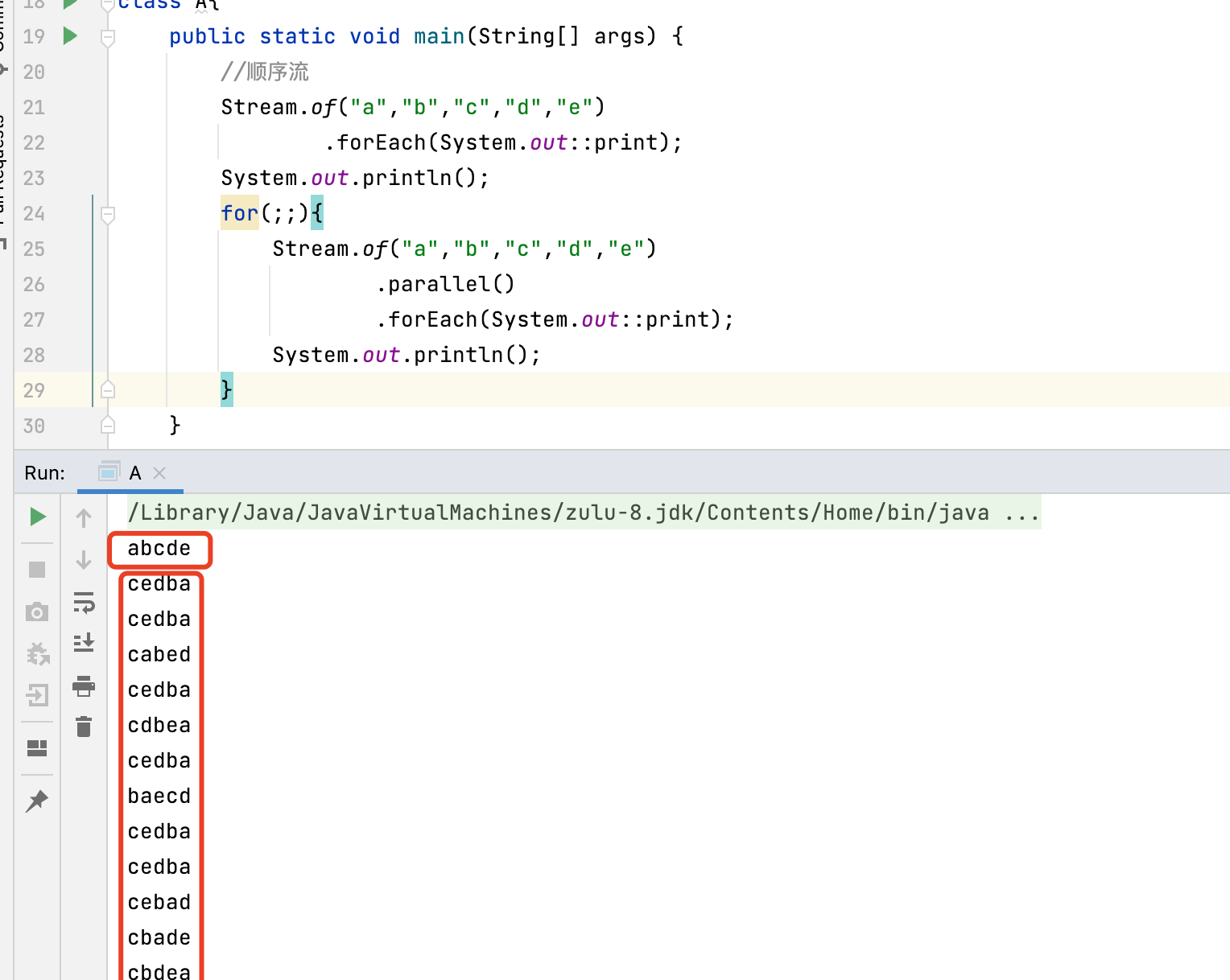
如上图
- 顺序Stream的结果是按照顺序预期的
- 并行流每次执行的结果都是无法预知的
并行流更适合于处理顺序不重要且不需要保持状态(它们是无状态和独立的)的操作
示例
long start = System.nanoTime();
String first = Stream.of("a","b","c","d","e")
.parallel()
.findFirst().get();
double duration = Double.valueOf(System.nanoTime() - start) / 1000000;
System.out.println(
first + " found in " + duration + " milliseconds");
long start1 = System.nanoTime();
String any = Stream.of("a","b","c","d","e")
.parallel()
.findAny().get();
double duration1 = Double.valueOf(System.nanoTime() - start1) / 1000000;
System.out.println(
any + " found in " + duration1 + " milliseconds");

其输出结果如上图所示,并行Stream适合于处理顺序不重要且不需要保持状态,使用findAny ()
什么是有状态操作
Stream<T> distinct()
Stream<T> sorted()
Stream<T> sorted(Comparator<? super T> comparator)
Stream<T> limit(long maxSize)
Stream<T> skip(long n)
可能需要遍历整个流才能产生结果,所以它们不适合并行流
BaseStream其他方法
将并行Stream转换为顺行Stream
- 使用BaseStream接口的sequential ()方法
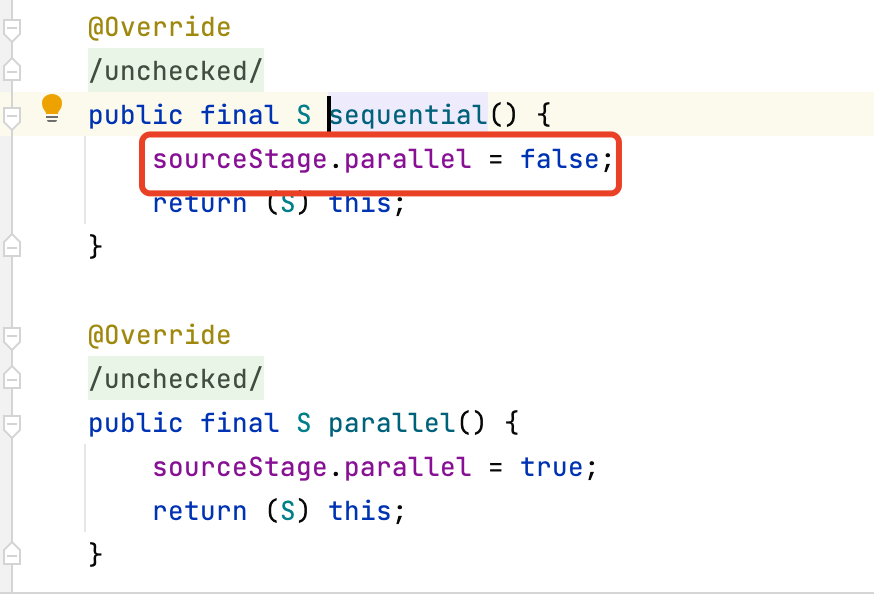
stream
.parallel()
.filter(..)
.sequential()
.forEach(...);
检查流是否为并行Stream
stream.parallel().isParallel();
将有序的Stream转换为无序的Stream(或确保Stream是无序的)
- 先执行有状态操作,然后将流转换为并行操作,在所有情况下性能都会更好,或者更糟,整个操作可能并行运行
//并行无序Stream
double start = System.nanoTime();
Stream.of("b","d","a","c","e")
.sorted()
.filter(s -> {
System.out.println("Filter:" + s);
return !"d".equals(s);
})
.parallel()
.map(s -> {
System.out.println("Map:" + s);
return s += s;
})
.forEach(System.out::println);
double duration = (System.nanoTime() - start) / 1_000_000;
System.out.println(duration + " milliseconds");
//有序Stream
double start1 = System.nanoTime();
Stream.of("b","d","a","c","e")
.sorted()
.filter(s -> {
System.out.println("Filter:" + s);
return !"d".equals(s);
})
// .parallel()
.map(s -> {
System.out.println("Map:" + s);
return s += s;
})
.forEach(System.out::println);
double duration1 = (System.nanoTime() - start1) / 1_000_000;
System.out.println(duration1 + " milliseconds");

并行版本花费的时间更多,且输出结果每次都是无序无法确定的
- 我们有一个独立的或者无状态的操作,在这个操作中顺序并不重要,
在一个很大的范围内计算奇数的数量,并行版本会表现得更好
double start2 = System.nanoTime();
long c = IntStream.rangeClosed(0, 1_000_000_000)
.parallel()
.filter(i -> i % 2 == 0)
.count();
double duration2 = (System.nanoTime() - start2) / 1_000_000;
System.out.println("Got " + c + " in " + duration2 + " milliseconds");
double start3 = System.nanoTime();
long d = IntStream.rangeClosed(0, 1_000_000_000)
.filter(i -> i % 2 == 0)
.count();
double duration3 = (System.nanoTime() - start3) / 1_000_000;
System.out.println("Got " + d + " in " + duration3 + " milliseconds");

这种情况下并行无序Stream话费的时间更短
并行流处理的结果是独立的,顺序不能得到保证
选择并行或顺行Stream
- 对于一小组数据,由于并行性的开销,顺序流几乎总是最佳选择
- 使用并行流时,避免有状态(如sorted()、FindaFirst)等操作
- 计算开销很大的操作,通常使用并行流具有更好的性能
并行Stream赋值reduce
在并发环境中,赋值是不好的,变更了变量的状态(特别是如果它们被多个线程共享),可能会遇到许多麻烦以避免无效状态。
Total t = new Total();
final Long[] a = {1L};
LongStream.rangeClosed(1, 10)
.forEach(i-> a[0] *=i);
System.out.println(a[a.length-1]);
LongStream.rangeClosed(1, 10)
.forEach(t::multiply);
System.out.println(t.total);
非并发情况下,这个代码的输出结果为362880.
但并行Stream在并发情况下不同,输出结果不确定
while (true) {
Total t1= new Total();
LongStream.rangeClosed(1, 10)
.parallel()
.forEach(t1::multiply);
System.out.println(t1.total);
}

reduce
创建中间值,然后将它们组合起来,避免了“排序”问题。
long tot = LongStream.rangeClosed(1, 10)
.parallel()
.reduce(1, (a,b) -> a*b);
System.out.println(tot);

最好避免共享可变状态,并使用无状态和独立的操作来确保并行流产生最佳结果。有时候reduce也会不正确
int total = IntStream.of(1, 2, 3, 4, 5, 6)
.parallel()
.reduce( 4, (sum, n) -> sum + n );

输出45而不是25,因为accumulator 函数独立地应用于Stream被分割的每个部分
总结
- 并行流将流拆分为多个部分。每个部分同时由不同的线程(并行)处理。
- 要从另一个流创建并行流,请使用parallel()方法。
- 要从集合创建并行流,请使用parallelStream()方法。
- 并行流更适合于处理顺序无关紧要且不需要保持状态的操作(它们是无状态和独立的)。
- 可以使用sequential()方法将并行流转换为连续流。
- 可以isParallel()检查流是否并行。
- 可以使用unordered()将有序流转换为无序流(或确保流无序)。
- 并行流的性能并不总是比顺序流好。
- 对于并行流,reduce()创建中间值,然后将它们组合起来,避免了“排序”问题,同时通过消除共享(变异)状态并将其保留在reduce进程中,仍然允许并行处理流。
- 唯一的要求是应用的归约运算必须是关联的:(a op b)op c==a op(b op c)。